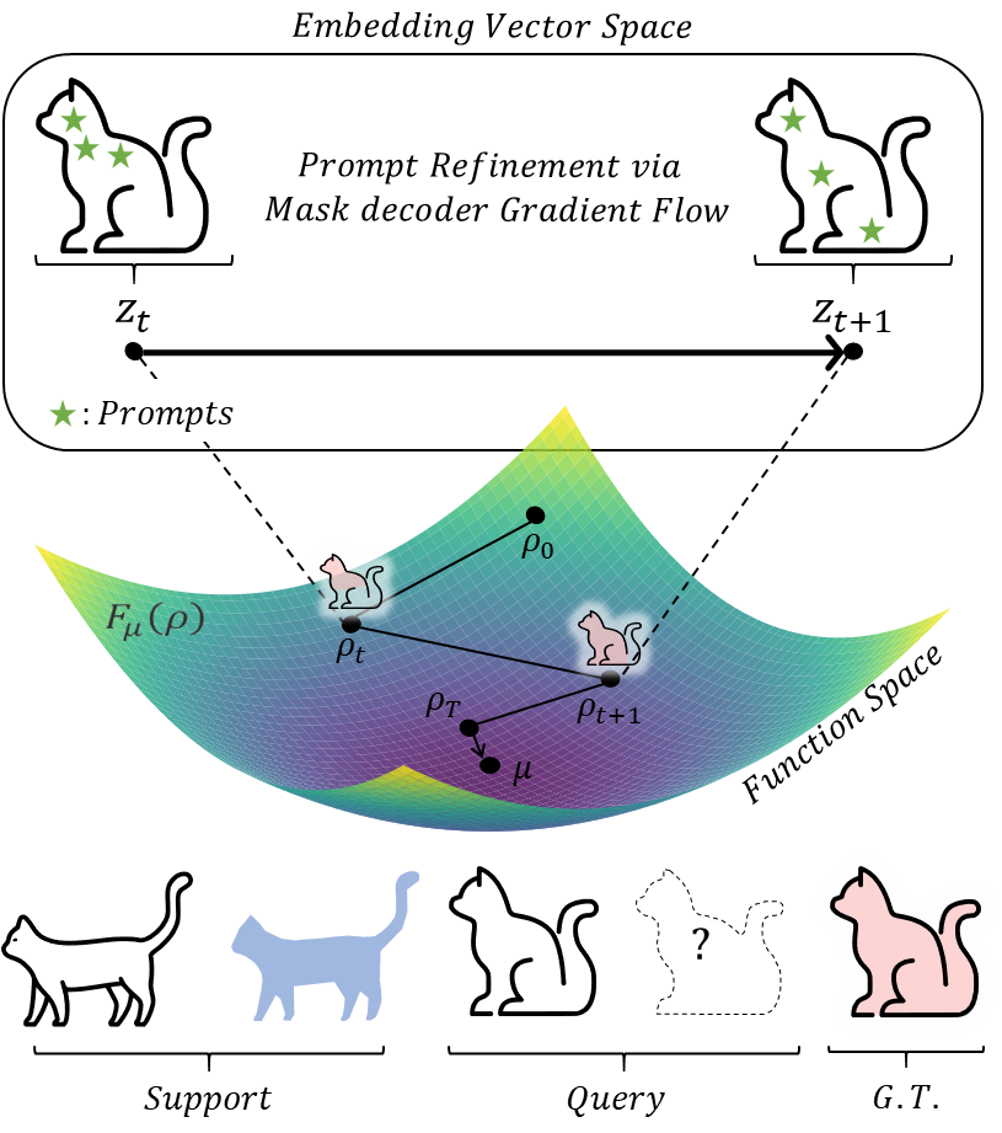
PR-MaGIC iteratively refines prompts for segmentation by updating the embedding vector
distribution ρt with mask decoder gradient flow.
This process minimizes the KL divergence between ρt and the target
embedding vector distribution μ derived from the ground truth mask.
At each iteration t, given an initial set of prompts and their corresponding
segmentation masks, the embedding vector zt is updated along the
gradient flow derived from the mask decoder, which in turn updates ρt.
(a) Support Image
(b) PerSAM-F
(c) Matcher
(d) PR-MaGIC (Ours)
(e) Ground Truth
Example of prompts (green dots) and segmentation results (red masks).
(b) & (c) show misaligned prompts and degraded segmentation from PerSAM-F and Matcher,
while (d) PR-MaGIC successfully captures the full extent of the elephant.
Abstract
Visual Foundation Models (VFMs) such as the Segment Anything Model (SAM) have significantly advanced broad use of
image segmentation. However, SAM and its variants necessitate substantial manual effort for prompt generation and
additional training for specific applications. Recent approaches address these limitations by integrating SAM into
in-context (one/few-shot) segmentation, enabling auto-prompting through semantic alignment between query and
support images. Despite these efforts, they still generate sub-optimal prompts that degrade segmentation quality
due to visual inconsistencies between support and query images.
To tackle this limitation, we introduce PR-MaGIC
(Prompt Refinement via Mask Decoder
Gradient Flow for In-Context Segmentation),
a training-free test-time framework that refines prompts via gradient flow derived from SAM's mask decoder.
PR-MaGIC seamlessly integrates into in-context segmentation frameworks, being theoretically grounded yet
practically stabilized through a simple top-1 selection strategy that ensures robust performance across samples.
Extensive evaluations demonstrate that PR-MaGIC consistently improves segmentation quality across various
benchmarks, effectively mitigating inadequate prompts without requiring additional training or architectural
modifications.
Key Contributions
🧪
Training-free test-time refinement via gradient flow.
A novel training-free refinement method that updates the query embedding with a mask-decoder-driven gradient
flow and resamples prompts, improving segmentation quality without learnable parameters, architectural
changes, or extra data.
🎯
Segmentation mask selection for robustness.
We generate candidate masks across T iterations and propose a simple top-1 support–query
similarity selection to choose the final mask, which safeguards against step-size sensitivity and
sample-dependent instability.
📐
Convergence analysis under a proximity assumption.
We provide a theoretical analysis showing that, when the initial embedding distribution is near a
decoder-optimal neighborhood, the entropy-regularized KL gradient flow drives exponential convergence
of the query embeddings.
Method
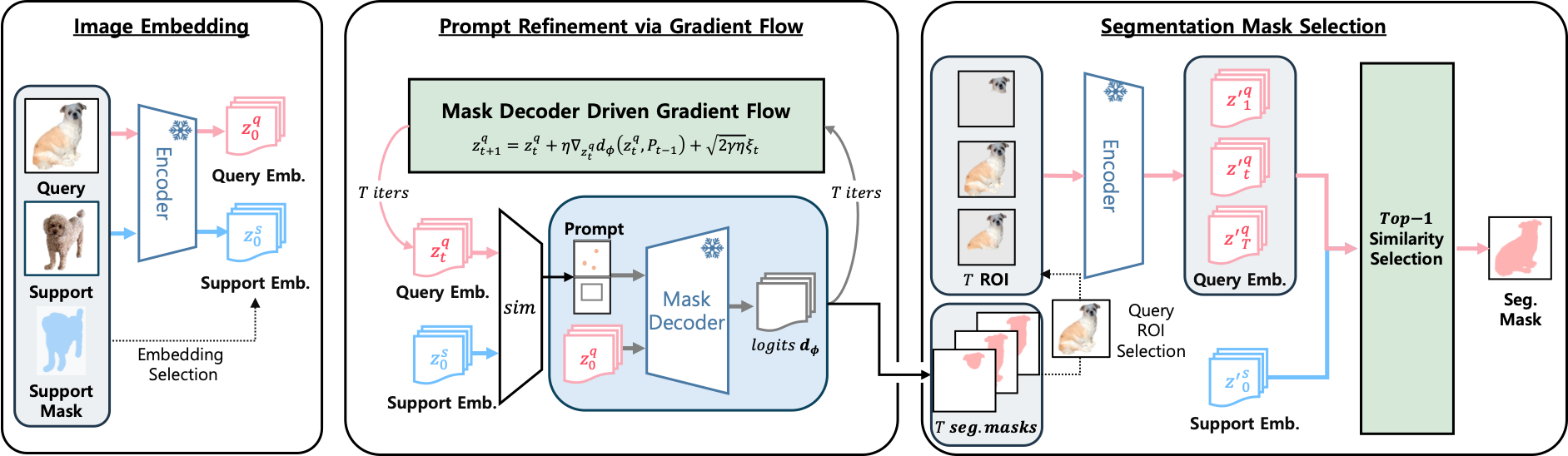
Overview of PR-MaGIC.
The Encoder maps support and query images to embeddings.
(1) Image Embedding: encoder maps the support and query images to embeddings
zs0 and zq0.
(2) Prompt Refinement via Gradient Flow: using the mask decoder logit dφ,
query embeddings are updated and prompts Pt+1 are resampled for t = 0…T−1,
forming a candidate mask set.
(3) Segmentation Mask Selection (Top-1): the mask whose mask-aware query embedding
has the highest similarity to the support embedding is selected as the final output.
1
Image Embedding
The encoder extracts query embedding zq0 and support embedding
zs0 from the query and support images.
2
Gradient Flow Refinement
Query embeddings are iteratively updated via mask-decoder-driven gradient flow.
At each step, new prompts are sampled from the updated embeddings.
3
Top-1 Mask Selection
From T candidate masks, the one with the highest support–query
similarity is selected as the final segmentation.
Entropy-Regularized KL Gradient Flow
PR-MaGIC minimizes the entropy-regularized KL-divergence between the target distribution μ and the
candidate distribution ρ:
where η > 0 is the step size, φ denotes the mask decoder parameters, and γ controls
entropy regularization. This theoretically supported flow drives query embeddings toward a
decoder-optimal neighborhood, effectively mitigating sub-optimal initial prompts.
Quantitative Results
mIoU (%) on six benchmark datasets.
B = Baseline, T = PR-MaGIC with Top-1 selection,
O* = PR-MaGIC with Oracle selection.
Bold indicates T values that improve over baseline.
Method
(a) Semantic Segmentation
(b) Part / Fine-grained Segmentation
FSS-1000
COCO-20i
LVIS-92i
PACO-Part
PASCAL-Part
DIS5K
B
T
O*
B
T
O*
B
T
O*
B
T
O*
B
T
O*
B
T
O*
PerSAM-F
58.41
67.19
72.45
44.64
46.83
51.74
42.37
44.48
47.29
39.60
40.72
43.39
42.72
43.87
46.43
46.82
49.99
53.46
Matcher (1-shot)
92.08
92.06
93.55
69.53
71.23
76.14
59.39
61.52
64.75
50.27
54.08
56.71
54.76
58.28
61.13
46.65
55.08
58.10
Matcher (5-shot)
93.26
93.41
94.32
67.69
70.74
74.88
57.14
60.79
63.88
48.66
53.15
55.30
54.54
59.27
61.55
—
—
—
Qualitative Results
PR-MaGIC (Refined) consistently produces more complete and accurate segmentations compared to
the baselines (PerSAM-F and Matcher) across both semantic and part segmentation tasks.
Semantic Segmentation
PerSAM-F + PR-MaGIC
Support Image
Baseline (PerSAM-F)
Refined (Ours)
Ground Truth
Matcher 1-shot + PR-MaGIC
Support Image
Baseline (Matcher)
Refined (Ours)
Ground Truth
Part Segmentation
PerSAM-F + PR-MaGIC
Support Image
Baseline (PerSAM-F)
Refined (Ours)
Ground Truth
Matcher 1-shot + PR-MaGIC
Support Image
Baseline (Matcher)
Refined (Ours)
Ground Truth
BibTeX
@misc{lee2026prmagicpromptrefinementmask,
title={PR-MaGIC: Prompt Refinement Via Mask Decoder Gradient Flow For In-Context Segmentation},
author={Minjae Lee and Sungwoo Hur and Soojin Hwang and Won Hwa Kim},
year={2026},
eprint={2604.12113},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2604.12113},
}
Acknowledgment
This research was supported by RS-2025-02216257 (70%), RS-2022-II220290 (20%),
and RS-2019-II191906 (AI Graduate Program at POSTECH, 10%).